I finally had a chance to use RxJava in a new Android project. Before that, I've read the doc and a few articles about it, and then I made my own experimentations. This blog post is about one of them. I assume you're already familiar with the basics of RxJava. In case you're not, there's plenty of articles out there to get you started!
The code in this article is written in Kotlin, the recent article from Jake Wharton made me want to try it out.
Usecase
For this experiment, we'll create a function which computes additionnal information on a given directory: its size on disk, and how much files it contains. For this we'll have to recursively analyze all its files and subdirectories.
Get started
Here's the structure to hold file information and the function signature we want.
// FileInfo references a file and add additional information to it
data class FileInfo(val file: File,
var bytes: Long = 0,
var filesCount: Long = 1)
// A function to compute a FileInfo out of a file
fun fileToFileInfo(file: File): Observable<FileInfo> { ... }
Kotlin is out of the scope of this article. But just to make it clear:
FileInfois a class with 3 fields (called "properties" in kotlin), and because it's adata class, it automatically hastoString(),hashcode()andequals()implemented using these properties.bytesandfilesCountboth have a default value, so for example an empty file or directory can be created usingFileInfo(File("path/to/file")).
Usage
We'll use it in a good old main function.
fun main(args: Array<String>) {
Observable.just(File("/Users/joan/Dropbox"))
.flatMap({ fileToFileInfo(it) })
.subscribe(
{ fileInfo -> println(fileInfo) },
{ throwable -> throwable.printStackTrace() })
}
And the output should look like this, thanks to the automatically generated toString() method of FileInfo:
FileInfo(file=/Users/joan/Dropbox, bytes=991505075, filesCount=7402)
Implementation
Ok so now, let's see how to implement fileToFileInfo. An old way to do this kind of thing would be to use a recursive function. On very deep file hierarchies, a recursive function would cause a StackOverflow to be raised, but we'll assume it wont for the sake of the exercise.
fun fileToFileInfo_old(file: File): FileInfo {
if (file.isFile()) return FileInfo(file, file.length())
else if (file.isDirectory()) {
val fileInfo = FileInfo(file)
file.listFiles().forEach { subFile ->
val subFileInfo = fileToFileInfo_old(subFile)
fileInfo.filesCount += subFileInfo.filesCount
fileInfo.bytes += subFileInfo.bytes
}
return fileInfo
}
throw IllegalArgumentException("Neither file or directory: $file")
}
This is a very basic recursive function. If we're given an actual file, it's the stopping criterion, so we just return a FileInfo with the appropriate bytes count. If it's a directory we make the recursive call on each child and assemble the result in a FileInfo.
Now, let's transform this to something more reactive like.
fun fileToFileInfo(file: File): Observable<FileInfo> {
if (file.isFile()) {
return Observable.just(FileInfo(file, file.length()))
} else if (file.isDirectory()) {
return Observable.from(file.listFiles())
.flatMap({ fileToFileInfo(it) })
.???
}
return Observable.error(IllegalArgumentException("$file is neither a file or a directory"))
}
Okay so at this point the recursion is all set up, but at ??? I still need to "merge" all the FileInfo streamed from the sub-files into one FileInfo for the current directory. The perfect fit for this is the reduce operator:
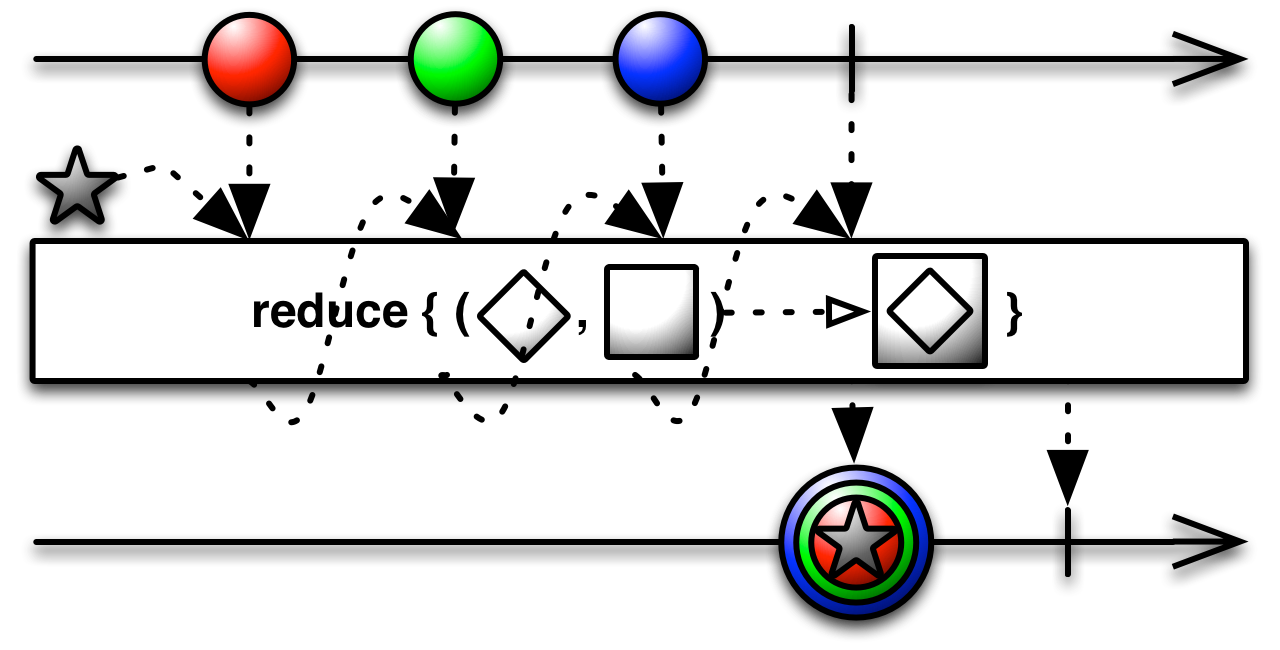
In our case the accumulator is a FileInfo, on which we'll increment bytes and filesCount each time a sub-FileInfo is streamed.
.reduce(FileInfo(file), { accumulator, subFileInfo ->
accumulator.bytes += subFileInfo.bytes
accumulator.filesCount += subFileInfo.filesCount
accumulator
})
You can find the whole code in this Gist.
What about threading?
I've shown this code to a few people and some of them thought it was running in parallel thanks to flatMap. Others thought that RxJava operates asynchronously by default. It doesn't.
I haven't used observeOn() and none of the operators I used (flatMap, reduce, from or just) operates on a particular scheduler, therefore the whole programs is synchronous. That means the call to subscribe is blocking. Actually this is fortunate: without that, the program would have exited the main() method and stopped before the end of the file analysis.
Modelization
The fact that the function is recursive makes it hard to create a mental model of it. So I had to take a pen and start drawing marble diagrams. I struggled a little bit but here's what came out.
{kind=link}

It's actually pretty simple once you see it, isn't it?
Parallelization
If you think of what we're doing, running through a hierarchy of files and accumulating data, it's easy to imagine it running in parallel. In practice, it's harder. First you should read this really good article by Graham Lea which shows some ways to achieve parallelism with RxJava.
Tools
The best way seems to use observeOn() or subscribeOn() to stream items on a different thread, and count on RxJava to merge the results coming from different threads in reduce. We'll stick to that.
We'll need some tooling to debug this. Kotlin extension functions, proved to be very helpful here!
val DEBUG = true
fun <T> Observable<T>.print(message: (T) -> String = { "" }): Observable<T> {
if (!DEBUG) return this;
return this.map({ println("[${Thread.currentThread().getName()}] ${message(it)}"); it })
}
It may seem obscure at first, but it adds a method to Observable called print(), which prints the given message each time an item is emitted, prefixed with the thread on which it happens. I won't elaborate on this as it's out of scope, so let's just see how to use it:
fun fileToFileInfo(file: File): Observable<FileInfo> {
if (file.isFile()) {
return Observable.just(FileInfo(file, file.length()))
.print({ "emit\t\t\t${it.file}" }) // HERE
} else if (file.isDirectory()) {
return Observable.from(file.listFiles())
.flatMap({ fileToFileInfo(it) })
.reduce(FileInfo(file), { acc, b ->
acc.bytes += b.bytes
acc.filesCount += b.filesCount
acc
})
.print({ "reduced\t\t${it.file}" }) // and HERE
}
return Observable.error(IllegalArgumentException("$file is neither a file or a directory"))
}
I ran the program on a directory structure like the one I used in the previous marble diagram.
root
├── file3
└── folder1
├── file1
└── file2
Output:
[main] emit /Users/joan/root/file3
[main] emit /Users/joan/root/folder1/file1
[main] emit /Users/joan/root/folder1/file2
[main] reduced /Users/joan/root/folder1
[main] reduced /Users/joan/root
FileInfo(file=/Users/joan/root, bytes=0, filesCount=5)
This was easily predictable. It starts by emitting the FileInfo of the "leaves" (the files). Once all files of a directory are emitted, they are reduced into a FileInfo of the directory, which is itself emitted. [main] is the thread on which the observable runs. As I said earlier, right now everything is single threaded and synchronous.
Just for the test, let's modify the main() method to run all the computation in another thread.
fun main(args: Array<String>) {
Observable.just(File("/Users/joan/root"))
.observeOn(Schedulers.io()) // HERE
.flatMap({ fileToFileInfo(it) })
.subscribe(
{ fileInfo -> println("[${Thread.currentThread().getName()}] $fileInfo") },
{ throwable -> throwable.printStackTrace() })
Thread.sleep(20000)
}
Note that I also changed the final println() to show which thread it runs on. As expected, now everything runs on one of the threads of Schedulers.io():
[RxCachedThreadScheduler-1] emit /Users/joan/root/file3
[RxCachedThreadScheduler-1] emit /Users/joan/root/folder1/file1
[RxCachedThreadScheduler-1] emit /Users/joan/root/folder1/file2
[RxCachedThreadScheduler-1] reduced /Users/joan/root/folder1
[RxCachedThreadScheduler-1] reduced /Users/joan/root
[RxCachedThreadScheduler-1] FileInfo(file=/Users/joan/root, bytes=0, filesCount=5)
We can now remove this observeOn() test.
Let's parallelize!
The main idea is that, each time we have to go inside a directory (listFiles()), we do it asynchronously. That way, when two directories are side-by-side, they should be processed in parallel.
For that, I send the listFiles() call in another thread using Observable.defer(...).subscribeOn(io).
fun fileToFileInfo(file: File): Observable<FileInfo> {
if (file.isFile()) {
return Observable.just(FileInfo(file, file.length()))
.print({ "emit\t\t${it.file}" })
} else if (file.isDirectory()) {
return Observable.defer({ // DEFER THE CREATION...
Observable.from(file.listFiles())
.flatMap({ fileToFileInfo(it) })
.reduce(FileInfo(file), { acc, b ->
acc.bytes += b.bytes
acc.filesCount += b.filesCount
acc
})
.print({ "reduced\t${it.file}" })
}).subscribeOn(Schedulers.io()) // ... ON ANOTHER THREAD
I added a few more files to the previous example to see what happens.
root
├── file3
├── folder1
│ ├── file1
│ └── file2
└── folder2
├── file4
└── file5
Output:
[RxCachedThreadScheduler-1] emit /Users/joan/root/file3
[RxCachedThreadScheduler-3] emit /Users/joan/root/folder2/file4
[RxCachedThreadScheduler-2] emit /Users/joan/root/folder1/file1
[RxCachedThreadScheduler-3] emit /Users/joan/root/folder2/file5
[RxCachedThreadScheduler-3] reduced /Users/joan/root/folder2
[RxCachedThreadScheduler-2] emit /Users/joan/root/folder1/file2
[RxCachedThreadScheduler-2] reduced /Users/joan/root/folder1
[RxCachedThreadScheduler-2] reduced /Users/joan/root
[RxCachedThreadScheduler-2] FileInfo(file=/Users/joan/root, bytes=0, filesCount=8)
That's a success! As you can see the files in folder1 and folder2 are emitted at the same time. As soon as file4 and file5 have been emitted they are reduced into folder2, even if folder1 have not completed yet. So that's true parallelism. Starting it with more logs, including forced sleep time, etc... confirms it.
Infinite threads...
Unfortunately, when I run it on a large file system, one time out of 10 it hangs. I mean that the final subscriber never gets any result. I haven't been able to figure out exactly what happens, but I noticed Scheduler.io() use a thread pool that grows as needed, without limit. That's a problem, because we made the algorithm to ask for a thread to that scheduler each time we encounter a directory. The JVM can't start an infinite number of threads, it's usually around 1000 threads max. Depending on how fast the program loops through the files, I think the Scheduler sometimes happens to start more than a thousand threads. That's incredibly bad!
The solution is to use a scheduler that limits the number of threads. It makes sense to use the number of cores on which the JVM runs. Hopefully this is quite trivial.
val scheduler = Schedulers.from(Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()))
Using this scheduler instead of Schedulers.io(), the program only uses 8 threads on my machine, and it never hangs.
That's it! You can find the final code here.
Conclusion
Thank you for reading so far. We've seen a usage of RxJava in a recursive function, we've had some thought on how to modelize it using a marble diagram, and we finally made it run in parallel. I'm really thankful you made it so far and I hope you learnt a few things. I did!